Cloud SQL Migration to Existing Instance With Near-Zero Downtime

Background
From 2020 to early 2022, a lot of companies, from startups to Big Tech, are spending flagrantly. They spend a ton of money on hiring top talents, office perks, and tech infrastructure. All the big Cloud Providers are enjoying this moment. Everyone was hosting their app infrastructure in the cloud.
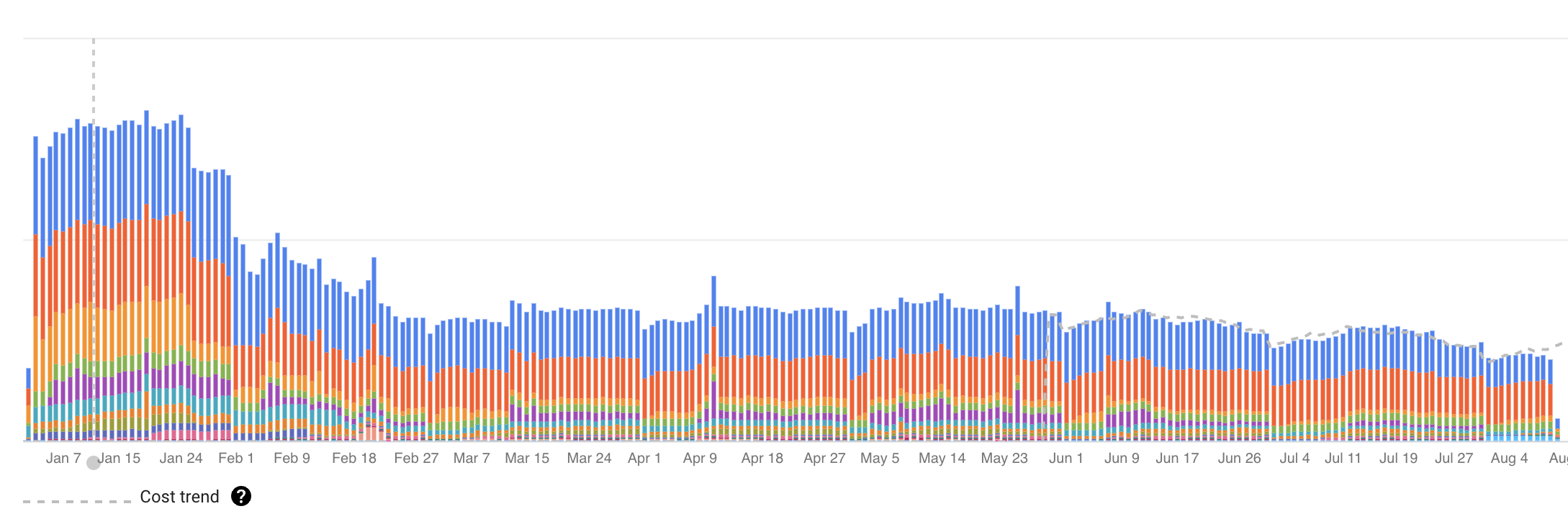
But the party was over towards the end of 2022. A lot of companies cut their spending. This is a journey where I cut our team’s Cloud Infrastructure cost. Toward the end, we cut the cloud bill by over 75%.
There are 3 interesting areas that we explored for cost savings. Database consolidation, Kubernetes cluster rightsizing, and autoscaling GitLab runner. In this article, I want to deep dive into the database consolidation process. I think the most challenging part of the journey.
For context, our backend infrastructure uses PostgreSQL for the database. My predecessor(s) designed the system with microservices architecture. For reasons unknown, the system evolved into a big pool of services, and each service has its database. With scaling in mind (I assume), it was set up so that each database has its own instance (CPU, memory, and disk) on our cloud provider (GCP). Additionally, each database has read replica, for even more scale (I think?). Everything is set up with Cloud SQL – the managed PostgreSQL product of Google Cloud.
Our backend had 9 database instances, each with read replicas (18 instances in total). To give an idea, GCP charges around $307 per month for an instance with 2 vCPU, 8 GB memory, and 100 GB disk. This is with high availability in our preferred region.
After getting access and all the credentials, I looked at the various metrics provided by the GCP. Utilization rate (CPU usage, memory usage, transaction/sec, etc). All metrics going back 6 months average 0.1x utilization, with the peak around 0.2. After spending more time with the team, I had a better understanding of our apps and services. I determined we don’t need this capacity.
My goal was to consolidate all our databases into a single Cloud SQL instance. It will have enough capacity for our production needs. It will be able to handle the peak traffic and be cost-efficient.
There’s no easy way to migrate from a Cloud SQL instance to an existing one. Google provides great tools to move data into or out of a Cloud SQL instance. But there’s no way to merge Cloud SQL instances into one. Such features might have been in their roadmap, but I don’t think we want to pay the bill for 18 instances while waiting.
With the goal set, I started researching. I explored different approaches to migrate PostgreSQL DB, with Cloud SQL restrictions in mind.For extra challenges (pain or fun, you tell me), I wanted to do it with minimal disruption for our customers. We want to have zero downtime or as little as possible. With production systems that handle financial transactions, this is the right approach.
After a ton of Google searches, I narrowed down our approach. We are going to use PostgreSQL logical replication tool called pglogical. This was my first time using this tool, but I know the theory enough to be able to wing it. We’ll improvise if we’re stuck. Since replication won’t impact the production data, it’s relatively safe.
The Process
After migrating 2-3 database instances, I was able to cut down the time from 2 weeks for 1 database, to 1 day for a database.
Here are the general steps.
Preparation
Create a new database in the target instance
Cloud SQL has this easy menu on their web console to create a new database in an existing instance.
Create a replication user with the right credentials
CREATE USER replication_user WITH REPLICATION IN ROLE cloudsqlsuperuser LOGIN PASSWORD '<replication_user_password>';Create the same database users in the target instance
This allows the app to connect to the database correctly without changing credentials. Cloud SQL also has this easy menu on their web console.
Export data from the source database to the target database
Again, Cloud SQL is nice in that it has an export and import button right up top.
Enable the pglogical plugin on all Cloud SQL instances
In Cloud SQL, I enabled the following database flags. Cloud SQL web console provides the value range as hints, I just used the minimum value (see utilization rate above for why I chose this). This needs a database instance reboot, so this is one of the downtimes that I had. I repeated this for all instances so I can control the downtime.
cloudsql.enable_pglogical
cloudsql.logical_decoding
max_replication_slots
max_worker_processes
max_wal_sendersCreate pglogical extension
Do this as the replication_user:
CREATE EXTENSION pglogical;By this point, I have a copy of the source_db in the target_db. However, as new data is inserted into the source_db, the target_db starts lagging behind. Especially on tables that are write-heavy. I listed all my write-heavy tables in my notes for future use.
Replication
Create 2 pglogical nodes
One in the source_db, and another in the target_db. Use the internal IP address of the Cloud SQL instance to make sure they can connect to each other.
-- on source_db
SELECT pglogical.create_node(
node_name := 'provider',
dsn := 'host=<source_db_ip_address> port=5432 dbname=<database_name> user=replication_user password=<source_db_replication_user_password>'
);
-- on target_db
SELECT pglogical.create_node(
node_name := 'subscriber',
dsn := 'host=<target_db_ip_address> port=5432 dbname=<database_name> user=replication_user password=<target_db_replication_user_password>'
);
On the source_db, add all tables and sequences to the replica set
In my case, since I have everything on the default schema, I use the following query.
SELECT pglogical.replication_set_add_all_tables('default', ARRAY['public']);
SELECT pglogical.replication_set_add_all_sequences(set_name := 'default', schema_names := ARRAY['public'], synchronize_data := true);
SELECT pglogical.synchronize_sequence( seqoid ) FROM pglogical.sequence_state;On the target_db, create a pglogical subscription
This is one of the most complicated parts. Not because it’s hard, but it’s dependent on how the database is set up. Even with only 2 users, a few tables, and a few sequences in Postgres, it was a lot of trial and error for me.
-- on target_db
SELECT pglogical.create_subscription(
subscription_name := '<subscription_name>',
provider_dsn := 'host=<source_db_ip_address> port=5432 dbname=<database_name> user=replication_user password=<source_db_replication_user_password>'
);Depending on the outcome, I checked whether your subscription was replicating or down.
-- on target_db
SELECT * FROM pglogical.show_subscription_status('<subscription_name>');Additionally, I often had to resynchronize the subscription, using this query:
SELECT * FROM pglogical.alter_subscription_synchronize('<subscription_name>');
SELECT * FROM pglogical.wait_for_subscription_sync_complete('<subscription_name>');There are a few common issues that I encountered:
- Permission issue
For this, there are a couple of things I check. Basically, I want to make sure mysource_db_replication_userhas read privilege on all tables and sequences. Additionally,target_db_replication_userhas write privilege on all tables and sequences. I checked thepglogical.queuetable and the error log for hints on which table I need to grant privilege to. - Duplicate key issue
This happens when mytarget_dbcan't insert new data because the primary key (id) already exists. My solution was to truncate the table and resynchronize.TRUNCATE <table_name> RESTART IDENTITY, recreate the subscription, thenSELECT * FROM pglogical.alter_subscription_resynchronize_table(<subscription_name>, <table_name>) - Table out-of-sync issue
You can use the samepglogical.alter_subscription_resynchronize_tableas above. I do this for write-heavy tables that I noted above. - Connection timeout issue
For this, I changed the database instance flag from the Cloud SQL web console and setwal_sender_timeoutto 5 minutes.
Validate replication
Make sure I have all tables have the same row count, and that the most recent rows are replicated. Additionally, validate sequences, indexes, views, and functions (if my database has them).
By the end of this step, I had 2 databases in 2 separate Cloud SQL instances, replicating.
Switchover
After everything is set up and the pglogical subscription is replicating, it’s time to update the app to use the target_db.
Since we use Kubernetes, this step is simple. I changed the configuration of the app to point to the target_db IP address. Then, I initiated a rolling restart. This ensures all ongoing requests are completed, and new requests go to new pods. The new pods will connect to target_db. Like all things migration, the best practice is to choose the time when traffic is low.
As with all config changes, it is wise to observe error logs of the impacted systems. I found a couple of issues in my switchovers:
- Database permission issue.
Different from the replication permission issue above, my app does not use the replication user’s credentials. My app user didn’t have permission to a couple of tables intarget_db. I solved it by granting the appropriate permissions (read and write). A quick Google search gave me the Postgres command to do it. - Duplicate keys error.
This is an issue with the Postgres sequence. In my case, my sequence didn’t have the right next value, so inserts were failing because new data didn’t have a unique id. I fixed it with a simple Postgres query
SELECT setval('table_name_id_seq', (SELECT MAX(id) FROM table_name)+1);By the end of this step, I observed that the source_db has little to no traffic. I observed the following metrics: transaction/sec, disk read, disk write, and connections.
Decommission
First, on the target_db, drop the pglogical subscription and node.
SELECT * FROM pglogical.drop_subscription('<subscription_name>')
SELECT * FROM pglogical.drop_node('subscriber');Then, I just stop and delete the source_db instance. This is the most satisfying, yet scary part. I validated that all the data are copied over, and services are working fine with the new database. Yet, it is still scary to delete a database instance. I stopped the instance, and delete the instance in the GCP console.
I observed the billing usage a couple of days after to see the satisfying drop in daily cost.
I go back to step 1, and repeat several more times, for all our migration targets.
The Results
Going from 9 instances with read replicas to a single instance is a significant cost savings. I choose high availability so that GCP hosts it in multiple zones. This is still a production system, and we need the availability.
With this approach, I managed to mitigate the downtime to a single database restart per instance. This is because the PostgreSQL instance requires a restart to enable the pglogical plugin.
Besides cost savings, I learned a lot about cloud infrastructure, Cloud SQL, and PostgreSQL. Their characteristics, limitation, and constraints are interesting. I learned more about capacity planning and the tradeoff between scale and cost.